最近几个项目都是React Native,所以对React的执行机制越来越好奇,比如为什么React Native也要先import React?为什么看起来声明周期没什么差别,但是渲染的结果(标签)却完全不同?怀着这些疑问,决定还是再看一下代码。之前草草撸过一遍基本操作,对结构和流程有个大概轮廓,但都只是粗浅的了解。尤其对于16.x以来的Fiber,还是一片广阔的未知,正好趁着这个机会,一起看一下。
React版本:react-16.9.0
主要工具:VS code,chrome
调度(reconciliation)方式
我知道,reconciliation有的叫“协调算法”,有的叫“一致性处理”,大概意思都是协调组件的集合和渲染,我这里翻译成“调度”可能也不是很确切,意会即可。
两篇文章供参考,这部分概念较多,所以很多内容来源于此:
-> React Fiber Architecture
-> The how and why on React’s usage of linked list in Fiber to walk the component’s tree
它干什么用?
简单来说,它负责把用户输入的React组件,组织成一棵树并保存到内存,然后通过渲染器(renderer)转化为目标平台可用的app节点结构。以及当有更新(通常是setState)过来的时候,会生成一棵新树。这时候就需要某种算法来对比两棵树,然后决定采取什么策略来更新最终渲染的app。
具体来说,调度方式包括了树的差异(diff)计算,生命周期函数的调用,以及使用不同的渲染器(如react-dom或react-native)更新节点的任务。【更多介绍】
基本上,react的调度方式在不同平台是一样的,不同的是渲染器(如浏览器DOM渲染器和RN渲染器)。它将这两个过程完全分开。所以从原理上来说,我们也可以自己实现一个renderer(比如代码库里用于测试的react-noop-renderer)。但是由于React没有对开发者开放过多的API,所以如果想这么做,可能要啃一些代码。
它和Fiber有什么关系?
react 16把默认的调度方式从stack切换到了Fiber。
在这部分开始前,我们要先知道什么是调用栈,以及有什么痛点。
调用栈(call stack)用来跟踪程序的执行,比如在代码中打个断点,debug就能看到函数调用流程。当一个函数执行时,对应的stack frame会压入栈,代表函数所进行的工作。
当处理UI时,通常会同时处理很多的工作,对React来说,嵌套越深的App就意味着更深的调用栈(如下面react-15-stable的图),这就可能产生动画掉帧的问题。而且,栈里的一些工作可能并不是必须的,可能会被后来的update冲掉。
现代浏览器(以及RN)实现了解决这个问题的API:requestIdleCallback用来在空闲时调度低优先级的function;requestAnimationFrame用来调度高优先级的function。但是由于这些API可供使用的时间都是碎片化的,所以为了使用它们,就需要把渲染任务分解成渐进式的小单元。如果依旧使用之前的stack机制,无法实现这个功能。
之前是什么样子呢?
在React 16之前,默认的stack使用了堆栈结构,当render过程中,发现一个子节点,就push到child里,接着向下递归直到没有子节点,由此生成了一个自顶向下的树形结构。这棵树是依赖于内置堆栈的同步递归模型(synchronous recursive model)。啥叫同步递归模型?举个例子,平时debug打断点的时候,能看到自调用函数向上的完整的调用栈(call stack)。
缺点很明显,当来了一个data更新,会自上而下生成一棵新的树,然后开始两棵树的差异(diff)对比,这时的工作是同步的,不太可能处理到某个节点,暂停去做另外的工作,而后转回来继续处理。而想保存整个调用栈里的各级状态,需要做大量额外工作。如果在这个同步任务执行时,有用户输入等事件进入,由于主线程正忙着处理这个任务,就会导致卡顿或者失去响应。
简单来说,同步顺序执行直至栈空。
所以Fiber应运而生。它专为React组件设计,每个fiber都可以看作一个虚拟的stack frame。这些stack frames都被放在内存里,供随时调用。
Fiber使用了稍微复杂的结构来处理:每个组件都对应一个Fiber节点,其中包含祖先-兄弟-孩子三个指针,由此组成链表结构,来实现这棵树。另外,用一个FiberRootNode来保存整个链表当前的状态,以属性current以及其他状态位指示当前处理的位置。
由于使用了Fiber,得以随时知道整棵树执行到哪个节点,以及state的状态,这使得更多功能的实现成为可能:并发模式,错误边界处理等。
虽然Fiber改变了React节点树的构建和diff机制,但是更上层的算法(戳 这里)逻辑基本没大变化,它基于两个最基础的假设:
1、不同的组件类型会生成不同的子树。此时不会去对比子树,而是重新生成一棵新的来取代。
2、列表(lists)的对比通过keys来进行,因此keys需要“稳定,可预测,且唯一”。
Fiber和之前的调度方式的直观差别?
以一个简单的组件来说明。为了直观,只列出最后的结构,省略组件的声明。
value
下面的瀑布图来自chrome devtools - performance。
react-15-stable
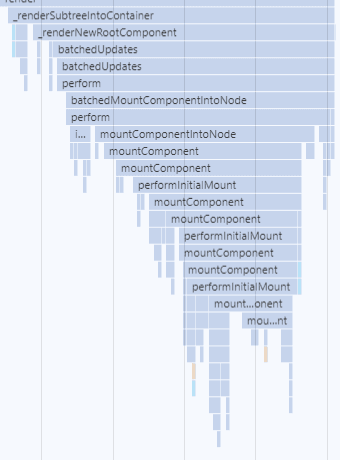
react-16.9.0


用16.9代码调试的时候,发现无论怎么添加代码逻辑,都是同步执行,没有看到并发的影子。这是因为React 16.9还未正式引进并发模式,估计正式启用要到React 17了。

如果有兴趣,可以手动启用试试效果,不过由于unstable,不建议在生产环境开启。
// Whole app (not final API) ReactDOM.unstable_createRoot(domNode).render(); // v16.11 更改为ReactDOM.createRoot
Fiber组织方式
还是以上面例子,最终生成的树结构

FiberNode生成的树结构
由于核心算法没变,所以还是可以看作维护了两棵树:一棵以HostRoot为头部节点的current(原始FiberNode节点)树,一棵是workInProgress(工作节点)树,两棵树通过各节点alternate属性关联。
惯例需要先走代码验证一下。
render legacyRenderSubtreeIntoContainer root = legacyCreateRootFromDOMContainer
这里两个函数被标记了legacy,说明这部分代码是遗留的,也就是说执行流程与之前比没变化,跳过。
首先会创建一个FiberRootNode,可以理解为一个容器,用于保存当前工作现场,方便pause/resume。
接着是一个叫HostRoot的FiberNode,tag被标记为3,type是null。相当于链表头。
创建之后即放入FiberRootNode的current。
FiberRootNode.current = HostRoot; HostRoot.stateNode = FiberRootNode;
renderRoot -prepareFreshStack // 用于生成空的栈结构
这一步主要是workInProgressRoot的相关属性设置,并从HostRoot创建第一个workInProgress(一个FiberNode类型的节点)。
// 用alternate字段,关联HostRoot和workInProgress workInProgress.alternate = current; current.alternate = workInProgress;
有了HostRoot,就可以在此之上构建整棵树了。整个过程作为一次update。一次update即包含data变更(通常是setState)到最后render的过程。
// Initial mount should not be batched. unbatchedUpdates(function () { updateContainer(children, fiberRoot, parentComponent, callback); });
-updateContainer -scheduleRootUpdate -createUpdate // (1)
-enqueueUpdate(FiberNode, update) // (2)
-scheduleWork(FiberNode, expirationTime) // (3) =scheduleUpdateOnFiber
-renderRoot
// (!)初次渲染时是同步的所以是workLoopSync,后续React版本会使用非同步的workLoop // 区别在于会在performUnitOfWork之后判断是否需要处理优先任务(shouldYield) -workLoopSync
workLoopSync这个函数只有3行
while (workInProgress !== null) { workInProgress = performUnitOfWork(workInProgress); }
performUnitOfWork会通过return第一个子节点,达到遍历的效果。而兄弟节点处理放在completeUnitOfWork里(这就是为什么组件根节点可以用数组放多个)。
-beginWork -updateHostRoot -reconcileChildren -workInProgress.child = reconcileChildFibers
reconcileChildFibers这里会按照子节点类型不同,生成不同type的FiberNode,当type是字符串时,child会为null,表示其为叶子节点,也是前面workLoopSync中遍历的终点。
整个执行流程:
beginWork... (HostRoot) beginWork... (IndeterminateComponent) beginWork... (IndeterminateComponent) beginWork... (HostComponent) completeUnitOfWork... (HostComponent) // 向上遍历设置父级effect,并处理兄弟节点(sibling),直到父级return为null commitRoot... (HostRoot)
附:React代码debug方式
虽然React管放文档关于代码的部分比较详细(在 这里),但是直接拿来看还是一脸懵逼。一个办法是,跑测试用例,直接debug也是理解代码的一个比较好的方式。
1、执行create-react-app;
2、从github上checkout一份代码下来,然后npm run build 编译react库。
进入build目录。分别cd react,cd react-dom,执行yarn link。创建快捷方式。
进入create-react-app的根目录,执行yarn link react react-dom。
准备工作执行完,就可以在App.js里打断点,开始debug。在源代码中打断点,步进,调试并观察。