写React代码的时候遇到一个state状态不一致的问题:如果state是对象(数组),用扩展运算符多次更新,一些状态被冲掉了。
class组件中,通常设置state的方法的步骤是
class Clock extends React.Component {
constructor(props) {
super(props);
this.state = {
foo: 1,
bar: 'a'
};
}
componentDidMount() {
this.setState({
foo: 2
});
this.setState({
bar: 'b'
});
}
render () {
return {this.state.foo} {this.state.bar}
}
}
此时会正常输出2 b,因为大概知道setState的状态是会merge到一起的。
但是放到函数组件里,如果直接写
const [data, setData] = useState({foo: 1, bar: 'a'});
useEffect(() => {
setData({
foo: 2
});
setData({
bar: 'b'
});
}, []);
foo: 2会被第二次的setData冲掉。
那么,如果想以对象(或数组)的形式来设置state,需要怎么操作呢?
1) 拆分为两个状态,foo和bar,以不同的方式来更新(显然跑题了)
const [foo, setFoo] = useState(1);
const [bar, setBar] = useState('a');
useEffect(() => {
setFoo(2);
setBar('b');
}, []);
2) 使用扩展运算符...
const [data, setData] = useState({foo: 1, bar: 'a'});
useEffect(() => {
setData({
...data,
foo: 2
});
setData({
...data,
bar: 'b'
});
}, []);
然后就遇到问题了,输出始终是1 b。然后自然猜测,setData是异步的,当操作到高亮部分的时候,上面的state还未实际发生作用,所以下面的state取到的并非最新的值。
真的是这样吗?如果查看官方文档,发现useState的设置,可以传递函数,即
const [data, setData] = useState({foo: 1, bar: 'a'});
useEffect(() => {
setData((prev) => ({
...prev,
foo: 2
}));
setData((prev) => ({
...data,
bar: 'b'
}));
}, []);
这时,又能正常输出2 b了。为啥呢?
官方解释是,不像setState,useState这个hook并不会自动的合并更新(merge update),所以可用用函数的方式来达到同样效果。
解决是解决了,但是感觉怪怪的。
set方法的执行流程
之前梳理过set流程,useState实际通过dispatchAction绑定dispatch回调的方式做了绑定,所以从这里开始看。
1) 直接使用对象setData({...})
一次更新的内容,会以循环链表的形式(queue)存储起来,最后统一遍历执行
queue,是在创建的时候(mountState,是useState的入口函数)就一并绑定的,存储在hook上
var queue = hook.queue = {
last: null,
dispatch: null,
lastRenderedReducer: basicStateReducer,
lastRenderedState: initialState
};
var dispatch = queue.dispatch = dispatchAction.bind(null, currentlyRenderingFiber, queue)
return [hook.memoizedState, dispatch] // dispatch即我们调用的setData
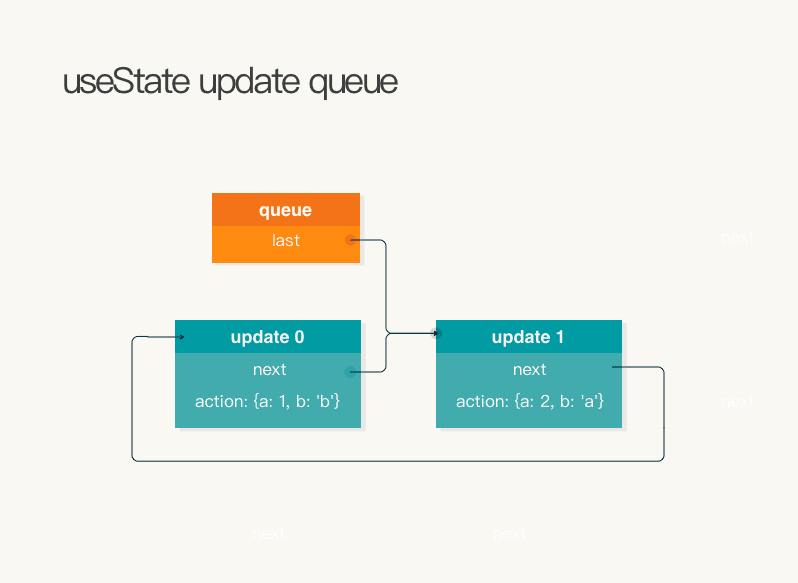
update queue循环链表结构
这个循环链表在每次调用setData,都会在上次操作节点的后面插入新的节点。遍历的时候从head的下个节点开始即可。
dispatchAction
_update.eagerState = _eagerState
renderWithHooks
-dispatcher.useState(initialState)
-updateState(initialState)
-updateReducer(basicStateReducer, initialState)
_newState = reducer(_newState, action)
=basicStateReducer(state, action)
return typeof action === 'function' ? action(state) : action;
第一次调用时,基础state是{foo: 1, bar: ‘a’},最后把newState设置为action即{foo: 2, bar: ‘a’};
第二次调用时,基础state是{foo: 2, bar: ‘a’},最后把newState设置为action即{foo: 1, bar: ‘b’}。
2) 使用functionsetData((prev) => ({...prev, {...}}))
dispatchAction
_update.eagerState = _eagerState // {a: 1, b: 'b'}
renderWithHooks
-dispatcher.useState(initialState)
-updateState(initialState)
-updateReducer(basicStateReducer, initialState)
// ... 触发update链表更新
_newState = reducer(_newState, action)
=basicStateReducer(state, action)
return typeof action === 'function' ? action(state) : action;
第一次调用时,基础state是{foo: 1, bar: 'a'},最后把newState设置为action(state),即函数执行结果{foo: 2, bar: 'a'};
第二次调用时,基础state是{foo: 2, bar: 'a'},最后把newState设置为action(state),即函数执行结果{foo: 2, bar: 'b'}。
action在这里,调用的是action,即我们传入的函数,而参数是{a: 1, b: 'b'},所以返回
{
...{foo: 2, bar: 'a'},
bar: 'b'
}
// 即
{
foo: 2,
bar: 'b'
}
可以看出,二者的区别仅仅在于最后对于basicStateReducer的使用。
为什么这么设计?
为什么以对象调用时,能取到上次的state,却直接抛弃不用,可以改吗?
在最后调用basicStateReducer(state, action)的时候,是传入了上次计算所得值state的,但是action是对象时,选择了直接抛弃,而使用新传入的值。
设想1. 把最后的basicStateReducer改成根据state来合并新对象
basicStateReducer(state, action)
return typeof action === 'function' ? action(state) : assign({}, state, action);
首次调用时,基础state是{foo: 1, bar: 'a'},action是{foo:2, bar: 'a'}。二者合并为{foo: 2, bar: 'a'};
第二次调用时,基础state是{foo: 2, bar: 'a'},action是{foo: 1, bar: 'b'}。二者合并,还是{foo: 1, bar: 'b'}。
即使调换顺序,使用assign({}, action, state),效果也是一样。
那么,像setState那样,每次setData只更新一个属性,然后合并可以吗?不行,因为这里的newState是基于上个链表节点的计算结果来的,只更新一个属性,会造成state丢失。
所以,主要原因在于函数是先绑定方法,setData的时候调用,而作为对象是直接参与计算的。
设想2. 把最后的basicStateReducer统一改为函数调用
不行,必须有一个和传递函数一样的函数,它满足两个条件:既能保留要更新的属性,又能把之前的state传递进来。
basicStateReducer(state, action)
return typeof action === 'function' ? action(state) : ((state) => ({...state, ...action})());
和设想1一样,不能一次更新一个属性(丢失state)。或者就利用对象属性对比,但是开销太大了。
class组件的state属性合并逻辑不一样吗
有个误解,class组件的state的状态合并和函数组件不一样。
因为class组件的state本身,就是作为一个对象存储的
this.state = {
foo: 1,
bar: 'a'
};
所以当更新的时候,setState({foo: 2})没问题,其实相当于是分成了两个state。如果要对应上面的例子,应该是
this.state = {
a: {
foo: 1,
bar: 'a'
}
}
componentDidMount() {
this.setState({
foo: {
...this.state.a,
foo: '2'
}
});
this.setState({
foo: {
...this.state.a,
bar: 'b'
}
});
}
输出依然是1 b,也没有"正确"合并。解决方法也是变为函数来设置。所以两个版本关于state更新这块,逻辑基本是一致的。
// react 15.6.0
_processPendingState: function (props, context) {
// ...
_assign(nextState, typeof partial === 'function' ? partial.call(inst, nextState, props, context) : partial);
// ...
}